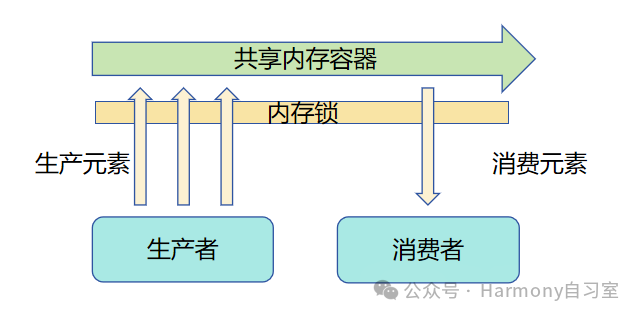
使用 8 张 A10 GPU(每张 A10 GPU 大约有 24 GB 的显存)来微调 70B 参数的模型会比较困难,主要原因是显存不足。像 70B 参数量级的模型(如 LLaMA-2 70B、BLOOM-176B)通常需要几百 GB 以上的显存,仅加载模型就需要大约 280-300 GB 的显存,因此即使 8 张 A10 显卡合计约 192 GB 显存,仍然难以直接加载和微调 70B 的模型。
不过,可以尝试以下几种方法来减少显存占用,从而使微调有可能实现:
1. LoRA(Low-Rank Adaptation)微调
- 方法:LoRA 是一种参数高效微调方法,通过只训练一部分参数而不更新所有权重,大大减少了显存需求。
- 实现步骤:
- 使用 Hugging Face Transformers 或 PEFT(Parameter-Efficient Fine-Tuning)库加载基础模型。
- 使用 LoRA 层覆盖模型的部分参数层,并只微调这些层。
- 优点:显著减少显存使用,通常可以在大约 24GB 的显存上进行 70B 的 LoRA 微调。
- 缺点:微调后模型会依赖 LoRA 层,推理时需要加载这些额外参数。
2. 分布式训练(Tensor Parallelism & Model Parallelism)
- 方法:将模型的不同部分切分到不同的 GPU 上,通过张量并行或模型并行的方法将显存负载分散到多张 GPU 上。
- 工具:使用 DeepSpeed(ZeRO Redundancy Optimizer 模式)、Megatron-LM 或 Colossal-AI 等工具,这些工具可以自动进行模型分割和内存管理。
- 优点:充分利用多个 GPU 的显存和计算资源。
- 缺点:配置较为复杂,且仍需充足的显存,并可能对带宽有较高要求。
3. FP16 或 INT8 量化
- 方法:将模型的参数量化为半精度(FP16)甚至 INT8,可以大幅减少显存需求。
- 工具:Hugging Face Accelerate 或 BitsAndBytes 库提供了 8-bit 量化支持。
- 优点:能大幅降低显存需求,虽然 70B 的模型仍然较大,但可能可以加载到 8 张 A10 GPU 中。
- 缺点:量化可能导致精度损失,尤其是对生成任务的影响较大。
4. 微调小型衍生模型
- 如果使用 70B 模型只用于特定任务,可能不需要微调整个模型。可以尝试仅微调小型衍生模型,例如 Distil 模型或剪枝模型,将 70B 的模型通过蒸馏、剪枝等方法缩小至 13B 或 30B,再进行微调。
5. 梯度检查点(Gradient Checkpointing)
- 方法:通过在反向传播时逐步计算梯度,而非一次性存储所有层的激活值,降低显存使用。
- 优点:能显著降低显存峰值需求,尤其适合深层网络。
- 缺点:增加训练时间,因为每次反向传播都要重新计算激活。
适用建议
对 70B 参数量级的模型,在 8 张 A10 GPU 上微调建议使用 LoRA 和 量化,可以先将模型转换到 FP16 或 INT8 格式,再通过 LoRA 微调一部分关键参数。这种方法相对更可行,且显存占用较小。